
Mạng neural hồi quy
Giới thiệu về Recurrent Neural Network (RNN)
Định nghĩa RNN:
Recurrent Neural Network - RNN là một loại mạng nơ-ron nhân tạo được thiết kế để xử lý dữ liệu tuần tự (sequential data). Điểm khác biệt chính của RNN so với các kiến trúc mạng nơ-ron khác như Multilayer Perceptron (MLP) hay Convolutional Neural Network (CNN) nằm ở khả năng ghi nhớ thông tin từ các bước thời gian trước đó. Điều này đạt được thông qua việc sử dụng các kết nối hồi quy (recurrent connections), cho phép thông tin ở các input phía sau sẽ nhận được cả thông tin ở các bước trước đó.
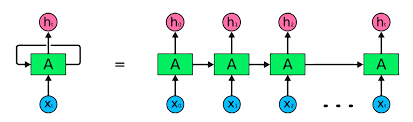
Trong hình minh hoạ, input \(x_t\) nhận dữ liệu đầu vào dạng chuỗi, ví dụ như nhiệt độ ngày thứ \(t\) đưa vào cell \(A\) tính toán và ra output là \(h_t\). Cell A tương tự như một Perceptron nhưng ngoài nhận dữ liệu \(x_t\), nó còn nhận thêm dữ liệu \(h_{t-1}\) (là output của việc tính nhiệt độ ngày trước đó). Output \(h_t\) được tính toán ngoài việc làm output còn là input của bước tiếp theo ứng với input \(x_{t+1}\).
Điểm lưu ý ở đây là ta chỉ có 1 cell \( A \), sau mỗi lần truyền input, ta sẽ nhận được 1 ouput \(h_t\), việc biểu diễn unfold bên phải cho ta hiểu cách dữ liệu được truyền vào. Việc này ngĩa là model chỉ dùng 1 bộ tham số trong cell \( A \) cho việc học nhiều input, đều đó giúp cho kích thước và số lượng input (timestep) có thể dài hay ngắn mà không cần cố định.
Mô hình RNN truyền thống cho phép nhận output của step trước vào làm input của step sau, qua đó giúp mô hình có thêm thông tin về các bước trước đó. Ít tham số hơn cũng giúp việc học nhanh hơn và mô hình cố gắng tìm được tham số tổng quát cho kiểu dữ liệu hiện tại.
Ưu điểm của RNN trong Xử lý Dữ liệu Tuần tự
RNN sở hữu nhiều ưu điểm vượt trội so với các kiến trúc mạng nơ-ron khác khi xử lý dữ liệu tuần tự:
-
Ghi nhớ thông tin từ quá khứ: RNN có khả năng lưu trữ thông tin từ các bước thời gian trước đó, cho phép nó hiểu được ngữ cảnh và mối quan hệ giữa các phần tử trong chuỗi dữ liệu.
-
Linh hoạt trong xử lý chuỗi có độ dài khác nhau: RNN có thể xử lý các chuỗi dữ liệu có độ dài khác nhau mà không cần phải điều chỉnh cấu trúc mô hình.
-
Chia sẻ tham số giữa các bước thời gian: RNN sử dụng cùng một tập hợp các tham số cho tất cả các bước thời gian, giúp giảm thiểu số lượng tham số cần học và tăng tốc độ huấn luyện.
Các kiến trúc RNN phổ biến
Cấu trúc của một Recurrent Neural Network Cell (RNN Cell):
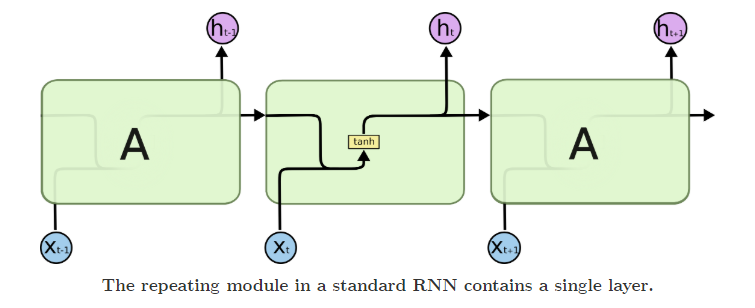
Trong một cell RNN, ta có 2 bộ tham số là \( W_x \) và \( W_h \) tương ứng với tham số của input hiện tại \( x_{t} \) và trạng thái trước đó \(h_{t-t}\) và bias \(b\) . Output của mạng RNN được tính như sau:
\[ h_t = \tanh(W_x x_t + W_h h_{t-1} + b) \]
Qua đó ta được \( h_t \) vừa là output của bước hiện tại vừa là input của bước tiếp theo. Đối với bước đầu tiên \( h_0 \) sẽ được khởi tạo ngẫu nhiên hoặc đặt 1 giá trị mặc định. Hàm \( \tanh \) thường được sử dụng để làm hàm kích hoạt (activation function) vì output trong range (-1: 1) hữu ích cho nhiều bài toán. Trên thực tế ta có thể thay thế các hàm kích hoạt khác cho phù hợp với bài toán và dữ liệu.
Long Short-Term Memory (LSTM):
Mạng Long Short-Term Memory (LSTM) là mạng RNN hồi quy trên các cell LSTM thay vì trên một RNN cell đơn giản. LSTM thiết kế để mô hình có thể nhớ được cả thông tin dài hạn trước đó và ngắn hạn từ bước gần nhất.
Cấu trúc của 1 cell LSTM được biểu diễn như sau:
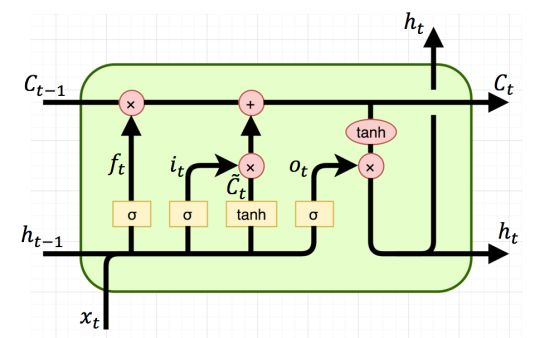
Tương tự với RNN cell, LSTM bổ sung thêm một đầu vào là \( C \) để biểu diễn cho bộ nhớ dài hạn, đầu vào \( h\) tương tự với RNN biểu diễn cho bộ nhớ ngắn hạn và nhiều phép tính phức tạp hơn, gọi là các gate, chúng ta sẽ cùng bóc tách ý nghĩa của cácstate và gate để xem cách LSTM cell hoạt động:
- Forget Gate: là hệ số quyết định bao nhiêu thông tin ở các bước trước đó sẽ được giữ lại, hệ số này được quyết định bởi input của bước đó và giúp cho mô hình điều chỉnh việc sử dụng bao nhiêu thông tin ở hiện tại và bao nhiêu thông tin ở quá khứ để cho ra output. \[ f_t = \sigma(W_{fx} x_t + W_{fh} h_{t-1} + b_f) \]
Hàm sigmoid \( \sigma \) được sử dụng vì có giá trị trong khoảng [0:1] biển thị cho tỉ lệ giữ lại thông tin của bước trước đó. 0 là bỏ qua hoàn toàn và 1 là giữ lại toàn bộ.
- Input Gate: tính thông tin của bước hiện tại, ta có 2 thông tin cần được tính là \( i_t \) và \( \tilde{C}_t \).
\[ i_t = \sigma(W_{ix} x_t + W_{ih} h_{t-1} + b_i) \]
\[\tilde{C}_{t}\]
\[= tanh(W_{cx} x_t + W_{ch} h_{t-1} + b_c)\]
Với \( i_t \) ở đây được gọi là Input gate, hoạt động tương tự như Forget gate \( f_t \) là cho phép bao nhiêu thông tin được giữ lại. \( \tilde{C}_t \) (candidate cell state) sẽ là thông tin hữu ích ở cell hiện tại, dùng để bổ sung vào bộ nhớ dài hạn Cell state ở bước tiếp theo.
- Cell State: như đã giới thiệu trước \( C_t \) được xem là bộ nhớ dài hạn, điểm khác biệt chính của LSTM với RNN truyền thống, \( C_t \) được tính như sau:
\[ C_t = f_i C_{t-1} + \tilde{C}_t i_t\]
Hiểu một cách đơn gian, cell state \( C_t \) là tổng thông tin của bước trước \( C_{t-1} \) và thông tin của bước hiện tại \( \tilde{C}_t \), 2 trọng số lần lượt là \( f_t \) và \( i_t \). Việc tính 2 trọng số riêng biệt giúp mô hình linh hoạt việc lựa chọn giữ lại bao nhiêu thông tin tại bước hiện tại và quá khứ.
- Output Gate:
output cho phép tính ra kết quả hidden state hiện tại \( h_t \) như sau:
\[ o_t = \sigma(W_{ox} x_t + W_{oh} h_{t-1} + b_o) \]
\[ h_t = o_t \tanh(C_t) \]
\( o_t \) được tính giống như cách tính của \( f_t \) và \( i_t \), việc sử dụng hàm sigmoid \( \sigma \) cho phép mô hình chọn bao nhiêu thông tin tại cell state \( C_t \) được sử dụng là hidden state tại bước hiện tại \( f_t \).
Khác nhau của \( h_t \) và \( C_t \)?
Ở mạng LSTM, \( h_t \) có ý nghĩa tương tự như \( h_t \) ở mạng RNN là dùng làm output của trạng thái hiện tại, và input của trạng thái tiếp theo, việc dùng output của trạng thái hiện tại làm input của trạng thái tiếp theo. \( C_t \) giống như 1 bằng chuyền dùng để đứa thông tin về các trạng thái trước đó đi đến trạng thái cuối cùng. Có thể hiểu \( h_t \) như bộ nhớ ngắn hạn và \( C_t \) như bộ nhớ dài hạn của model. Tuy nhiên, các thông tin này sẽ còn phụ thuộc vào giá trị của các gate (forget gate, input gate và output gate) điều chỉnh chứ không hoàn toàn tách biệt.
Gated Recurrent Unit (GRU):
Cổng truy hồi đơn vị Gated Recurrent Unit (GRU) được xem là một biến thể của mạng LSTM. Sử dụng ít cổng (gate) hơn, không dùng có Cell state \( C_t \) để giúp làm mô hình đơn giản hơn. Cấu trúc GRU mô tả như sau:
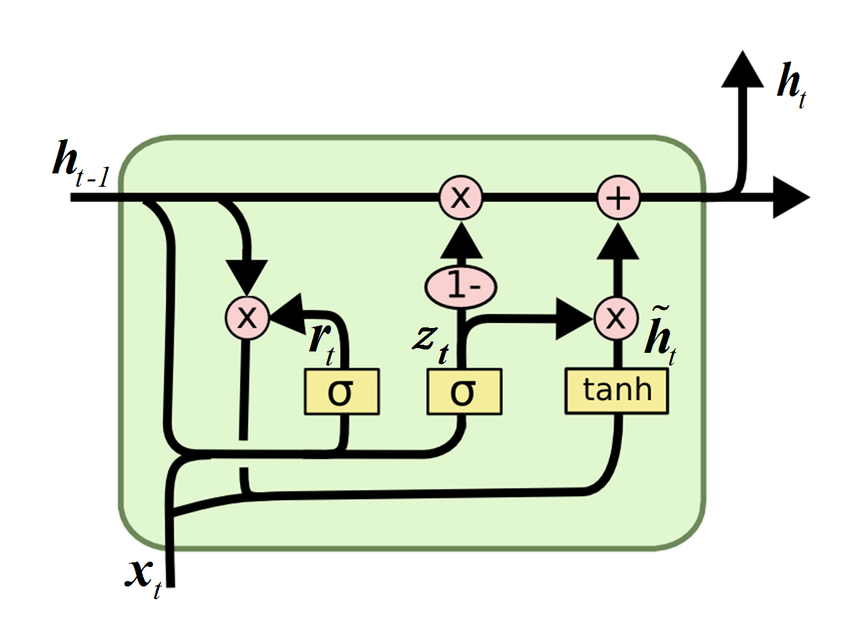
-
Update Gate \( z_t \): Quyết định mức độ thông tin từ hidden state trước đó \( h_{t−1} \) sẽ được giữ lại và mức độ thông tin mới sẽ được thêm vào.
-
Reset Gate \( r_t \): Quyết định mức độ thông tin từ hidden state trước đó\( h_{t−1} \) sẽ bị bỏ qua khi tính toán candidate hidden state \( \tilde{h}_{t} \).
Gộp \( C_t \) và \( h_t \) lại làm một giúp mô hình trở nên đơn giản, giúp huấn luyện nhanh hơn và phù hợp với các bài toán có dữ liệu không quá nhiều.
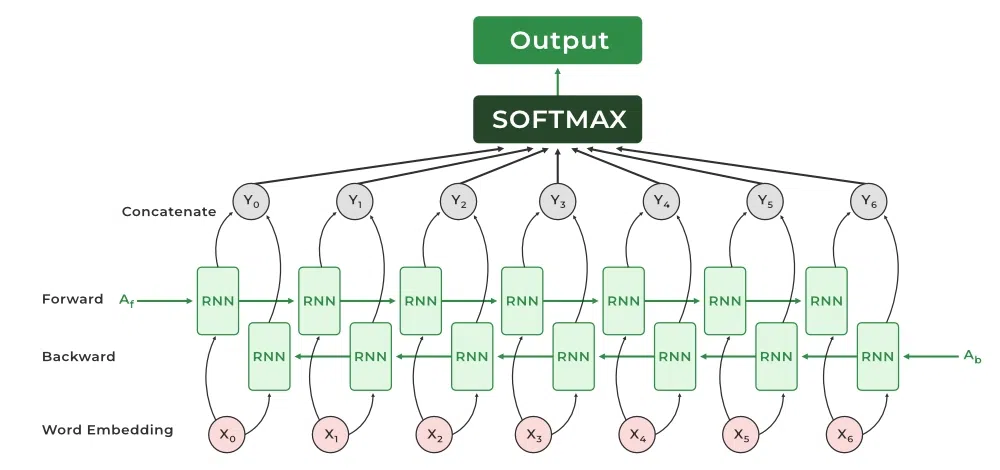
Bidirectional RNN (B-RNN):
Mô hình B-RNN là kết hợp thông tin từ cả quá khứ và tương lai để cải thiện dự đoán. Việc này phù hợp với các bài toán cần thông tin về cả phía trước lẫn phía sau của 1 chuỗi cho trước, ví dụ như một câu
Ứng dụng của RNN
Xử lý ngôn ngữ tự nhiên (NLP):
- Phân loại văn bản.
- Tạo văn bản (text generation).
- Dịch máy.
- Trả lời câu hỏi.
Nhận dạng giọng nói:
- Chuyển đổi giọng nói thành văn bản.
Dự báo chuỗi thời gian:
- Dự báo giá chứng khoán.
- Dự báo thời tiết.
Các mô hình dạng RNN có nhiều ưu điểm và thế mạnh, tuy nhiên cũng rất khó ứng dụng vì yêu cầu tính toán tuần tự vì dữ liệu cần phải lần lượt đi qua các cell để tính cho step tiếp theo. Tương lai, các mô hình dạng dựa trên Transformer sẽ có các ưu điểm để thay thế các mô hình RNN trong việc xử lý các bài toán phức tạp và yêu cầu xử lý lượng dữ liệu lớn một cách nhanh chóng hơn.
References
[1] Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT press.
[2] Nielsen, M. A. (2015). Neural networks and deep learning. Determination Press.
[3] Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. Nature, 323(6088), 533-536.
[4] Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780.
[5] Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078.
[6] http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
[7] http://karpathy.github.io/2015/05/21/rnn-effectiveness/
[8] http://colah.github.io/posts/2015-08-Understanding-LSTMs/
