
Transformer - Attention is all you need!
Trong bài viết này, chúng ta cùng đi qua tìm hiểu về một trong những kỹ thuật quan trọng nhất trong các mô hình ngôn ngữ hiện đại: Transformer. Bằng việt cùng nhau tìm hiểu qua paper Attention Is All You Need được Google Brain giới thiệu năm 2017.
Giới thiệu về Transformer
Các mô hình RNN như LSTM, GRU mang lại hiệu suất rất tốt cho các bài toán về xử lý chuỗi (sequence) nhờ cung cấp các phụ thuộc giữa các phần tử trong chuỗi. Tuy nhiên, RNN gặp nhiều hạn chế về mặc tốc độ tính toán, nhất là các chuỗi có đầu vào dài, mô hình sẽ phải tính tuyến tính lần lượt qua các phần tử để ra kết quả. Kiến trúc Transformer ra đời đã giúp loại bỏ hoàn toàn tính hồi quy (Recurrent) và chỉ dựa vào cơ chế Attention để vẽ ra các phụ thuộc toàn cục giữa đầu vào và đầu ra. Ngoài ra, Transformer cũng giúp mô hình có khả năng học được các phụ thuộc của 2 phần tử cách xa nhau 1 cách đơn giản mà không phải thông qua nhiều bước lặp của RNN.
Kiến trúc mô hình Transformer
Kiến trúc Transformer (hình dưới) được tuân theo kiến trúc Encoder (khối bên trái) và Decoder (Khối bên phải).
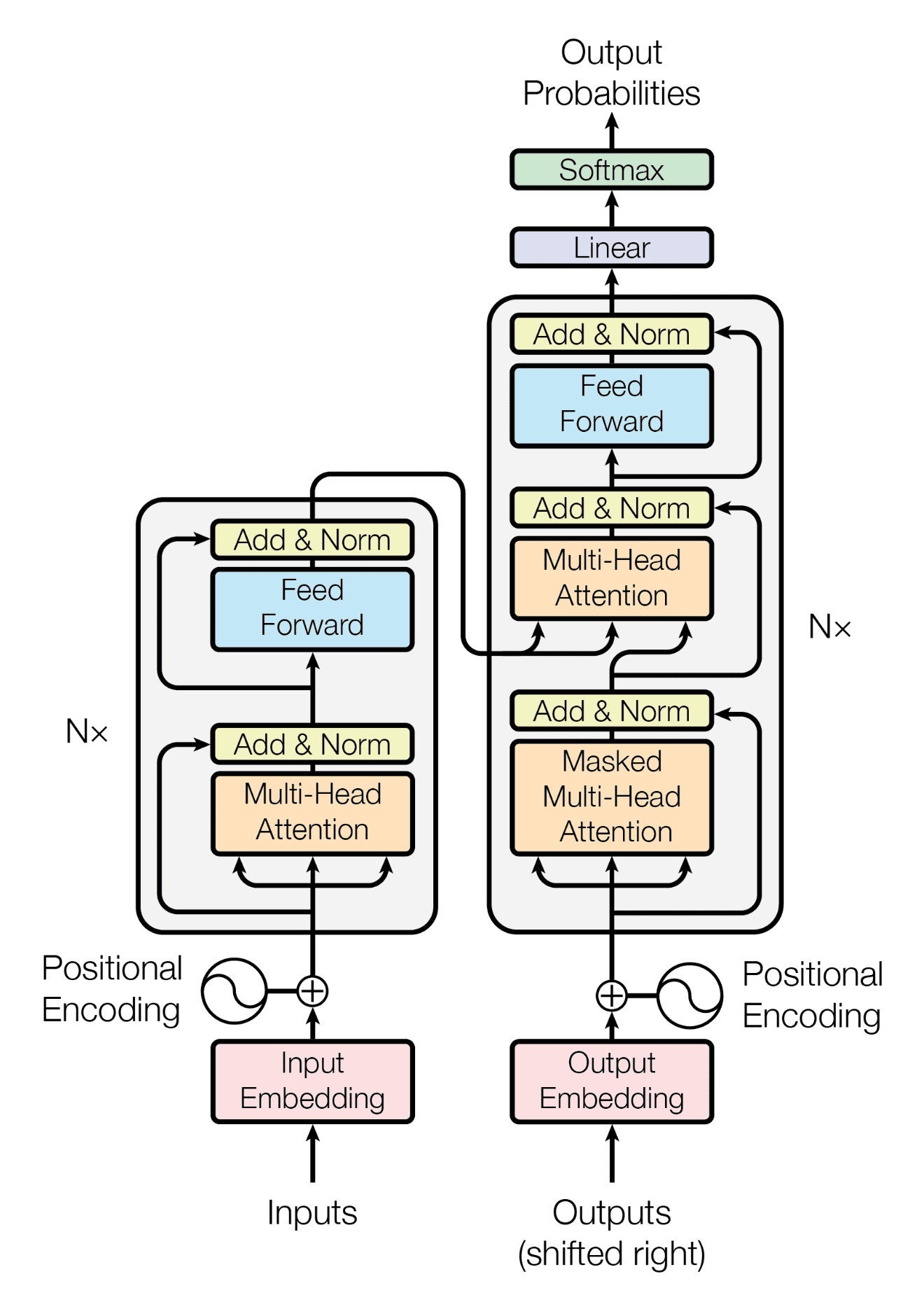
Encoder
Encoder là một lớp xếp chồng (stack) của \(N\) layer, mỗi layer chưa 2 layer phụ gồm:
- Một lớp
Multi-head self-attention - Một lớp
feed-forward network, một mạng cơ bản như MLP hay CNN.
Cả hai layer phụ này được theo sau bởi layer normalization giúp chuẩn hoá dữ liệu đầu ra.
Decoder
Có cấu trúc tương tự như 1 Encoder, bao gồm stack của \(N\) layer, tuy nhiên ta có thêm 1 sub layer đừng trước 2 layer Multi-head self-attention và feed-forward network, layer này được gọi là Masked multi-head self-attention. Khi dữ đoán phần tử (ký tự trong câu) thứ i trong mô hình, layer này sẽ cung cấp thông tin về i-1 ký tự đầu tiên, đảm bảo mô hình xử lý phần tử (ký tự trong 1 câu) dựa vào các thông tin trước đó.
Attention
Đây là phần đáng chú ý và cũng có lẻ là khó hiểu nhất của mô hình Transformer. Attention ở đây sẽ là một vector được tính bằng 3 vector khác gồm Query (Q), Key (K) và Value (V). Vector attention là tổng có trọng số của các vector value (V), với trọng số được tính bằng một phép tính của 2 vector Query (Q), Key (K).
Scaled Dot-Product Attention
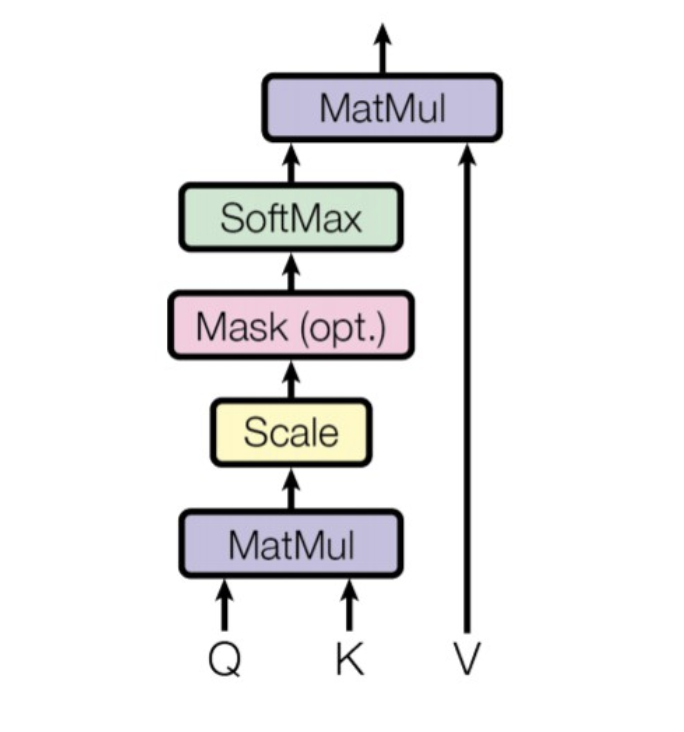
Công thức của lớp ` Scaled Dot-Product Attention` như sau:
\[ Attention(Q, K, V) = \text{softmax} \left( \frac{Q K^T}{\sqrt{d_k}} \right) V \]
Đầu vào, \(Q K^T\) là tích vô hướng (MatMul hay Dot-Product) của 2 vector \(Q\) và \(K\), tích này được chia với \(\sqrt{d_k}\) để tỉ lệ (Scaling), giúp đầu ra không bị quá lớn hoặc quá nhỏ. Đầu ra được áp dụng hạm softmax giúp biến đổi giá trị Scaled Dot-Product thành phân phối xác xuất (tổng bằng 1), đây sẽ là trọng số (weight) để tính tổng các vector values (V).
Output của \( \text{softmax} \left( \frac{Q K^T}{\sqrt{d_k}} \right) \) được nhân vô hướng với vector \(V \) và được vector attention.
Các phép tính ở một lớp ` Scaled Dot-Product Attention` đều là các phép tính đơn giản, hỗ trợ việc tính song song và dễ tối ưu để tăng tốc độ tính toán.
Vậy thì tóm lại \(Q, K, V\) là gì và output Attention có ý nghĩa gì?
Cho 1 câu có độ dài là \(n\), câu đầu vào được cho qua một mô hình nhúng (chuyển từ trong câu thành 1 vector, ví dụ như Word2Vec), mô hình embedding có \(m\) chiều. Output của câu sau khi qua mô hình embedding sẽ là ma trận \(X\) có kích thước nxm.
Mô hình sẽ tính được 3 ma trận \(Q, K, V\) bằng cách nhân \(X\) với lần lượt 3 ma trận tham số \(W_q\), \(W_k\), \(W_v\).
-
Query \(Q\): cung cấp thông tin về câu hỏi “từ nào có liên quan với từ hiện tại”
-
Key \(K\): chứa thông tin các từ còn lại, giúp trả lời câu hỏi “từ này liên quan bao nhiêu tới từ trong query”
Cả 2 vector \(Q\) và \(K\) sẽ được kết hợp để ra đầu ra có dạng một phân phối xác xuất của sự “liên quan” giữa các từ với nhau, kết quả này có kích thước nxn tương ứng là mỗi từ trong câu có mức “độ liên” quan với các từ còn lại như thế nào.
- Value: Có tác dụng gần giống như vector đầu vào X là chứa thông tin thực tế của các phần tử, tuy nhiên X được tính qua các layer để học thêm nhiều thông tin phù hợp hơn. X được sử dụng để tính toán đầu ra của lớp attention.
Lớp Scaled Dot-Product Attention tự sử dụng input của câu để học được sự liên quan giữa các từ với nhau.
Vector attention chứa một sự kết hợp có trọng số của các vector value (V) từ các phần tử khác nhau trong chuỗi đầu vào. Trọng số của mỗi value được xác định bởi điểm attention tương ứng, phản ánh mức độ liên quan của phần tử đó với phần tử đang được xem xét (query).
Nói cách khác, vector attention là một dạng “tổng hợp thông tin” từ các phần tử khác, nhưng thông tin này đã được lọc và điều chỉnh dựa trên mức độ liên quan của chúng với phần tử hiện tại.
Vector attention có ý nghĩa quan trọng trong việc giúp mô hình Transformer:
-
Nắm bắt các mối quan hệ ngữ nghĩa: Bằng cách kết hợp thông tin từ các từ liên quan, vector attention giúp mô hình hiểu rõ hơn về ý nghĩa của từ hiện tại trong ngữ cảnh cụ thể.
-
Giải quyết vấn đề phụ thuộc xa: Trong các câu dài, các từ liên quan có thể cách xa nhau. Vector attention cho phép mô hình “nhìn thấy” và kết hợp thông tin từ các từ ở xa nhau, giúp giải quyết vấn đề phụ thuộc xa (long-range dependencies) mà các mô hình truyền thống như RNN/LSTM gặp khó khăn.
-
Cung cấp thông tin ngữ cảnh phong phú: Vector attention cung cấp cho mô hình một biểu diễn phong phú về ngữ cảnh xung quanh từ hiện tại, giúp mô hình đưa ra quyết định chính xác hơn trong các tác vụ như dịch máy, phân tích cảm xúc, hay trả lời câu hỏi.
-
Tính linh hoạt và khả năng thích ứng: Trọng số attention được tính toán động dựa trên từng input cụ thể, giúp mô hình có thể thích ứng với nhiều loại dữ liệu và nhiệm vụ khác nhau.
Multi-Head Attention
Thêm nhiều lớp Scaled Dot-Product Attention song song nhau với kỳ vọng mỗi lớp sẽ học được các thông tin attention khác nhau. Output sẽ được tổng hợp lại theo dạng concat. \[MultiHead(Q, K, V) = Concat(head_1, …, head_h) * W^O \]
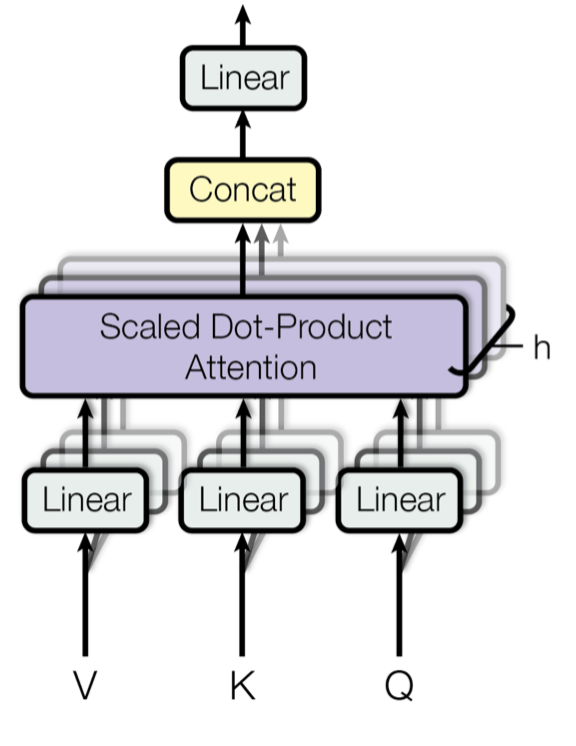
Multi-Head Attention giúp mô hình học được các biểu diễn phong phú hơn và cải thiện hiệu suất trên nhiều tác vụ NLP.
Position-wise Feed-Forward Networks
Output của lớp Multi-Head Attention sẽ được tiếp tục đưa qua các mô hình Feed-Forward, ở paper cụ thể là các fully connected layers. Lớp này cho phép mô hình học thêm nhiều thông tin và biểu diễn phức tạp hơn so với các thông tin ở đầu ra của Multi-Head Attention,
Positional Encoding
Trong kiến trúc Transformer, mặc dù mô hình đã có thể tự học được các tính liên quan và mối quan hệ giữa các từ trong câu (đối với bài toán xử lý ngôn ngữ). Các thông tin chính xác về vị trí của từ trong câu cũng giúp mô hình có thêm thông tin cho các task cần thông tin vị trí như Named Entity Recognition - NER.
Trong paper, tác giả sử dụng 2 hàm sin và cos khác tần số để biểu diễn vị trí của từ trong câu.
References
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
Alammar, J. (n.d.). The Illustrated Transformer. Retrieved from http://jalammar.github.io/illustrated-transformer/
The Annotated Transformer. (2018). Harvard NLP. Retrieved from http://nlp.seas.harvard.edu/2018/04/03/attention.html
