
BERT - Hiểu ngôn ngữ
Giới thiệu về BERT
BERT (Bidirectional Encoder Representations from Transformers) là một mô hình ngôn ngữ mạnh mẽ được phát triển bởi Google, dựa trên kiến trúc Transformer. BERT đã tạo ra một bước đột phá lớn trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP) nhờ khả năng hiểu sâu ngữ cảnh và ý nghĩa của văn bản.
Điểm mới của BERT so với Transformer gốc:
-
Mã hóa hai chiều (Bidirectional): Transformer gốc chỉ mã hóa văn bản theo một chiều (từ trái sang phải hoặc từ phải sang trái), trong khi BERT mã hóa theo cả hai chiều cùng lúc. Điều này cho phép BERT nắm bắt được ngữ cảnh đầy đủ của một từ dựa trên cả những từ đứng trước và sau nó, từ đó hiểu rõ hơn ý nghĩa của từ trong câu.
-
Học biểu diễn ngôn ngữ theo ngữ cảnh: BERT được huấn luyện trước trên một lượng lớn dữ liệu văn bản (Wikipedia, sách,…) bằng hai nhiệm vụ chính: MLM (Masked Language Modeling): Dự đoán các từ bị che đi ngẫu nhiên trong câu, giúp BERT học cách hiểu mối quan hệ giữa các từ. NSP (Next Sentence Prediction): Dự đoán xem hai câu có liên tiếp nhau hay không, giúp BERT hiểu được mối quan hệ giữa các câu. Nhờ quá trình huấn luyện trước này, BERT đã học được các biểu diễn ngôn ngữ phong phú, chứa đựng thông tin ngữ nghĩa và ngữ cảnh sâu sắc.
-
Hiệu suất vượt trội: BERT đã đạt được những kết quả vượt trội so với các mô hình ngôn ngữ trước đó (Word2Vec, GloVe và ELMo) trên nhiều nhiệm vụ NLP khác nhau, bao gồm phân loại văn bản, nhận dạng thực thể đặt tên, trả lời câu hỏi, phân tích tình cảm, và nhiều hơn nữa. Điều này cho thấy BERT có khả năng hiểu và xử lý ngôn ngữ tự nhiên một cách hiệu quả hơn
-
Ứng dụng đa dạng: BERT có thể được tinh chỉnh (fine-tuned) để thực hiện nhiều nhiệm vụ NLP khác nhau như phân loại văn bản, nhận dạng thực thể, trả lời câu hỏi, dịch máy, tóm tắt văn bản,… và đạt được hiệu suất vượt trội so với các mô hình trước đó.
Kiến trúc của BERT:
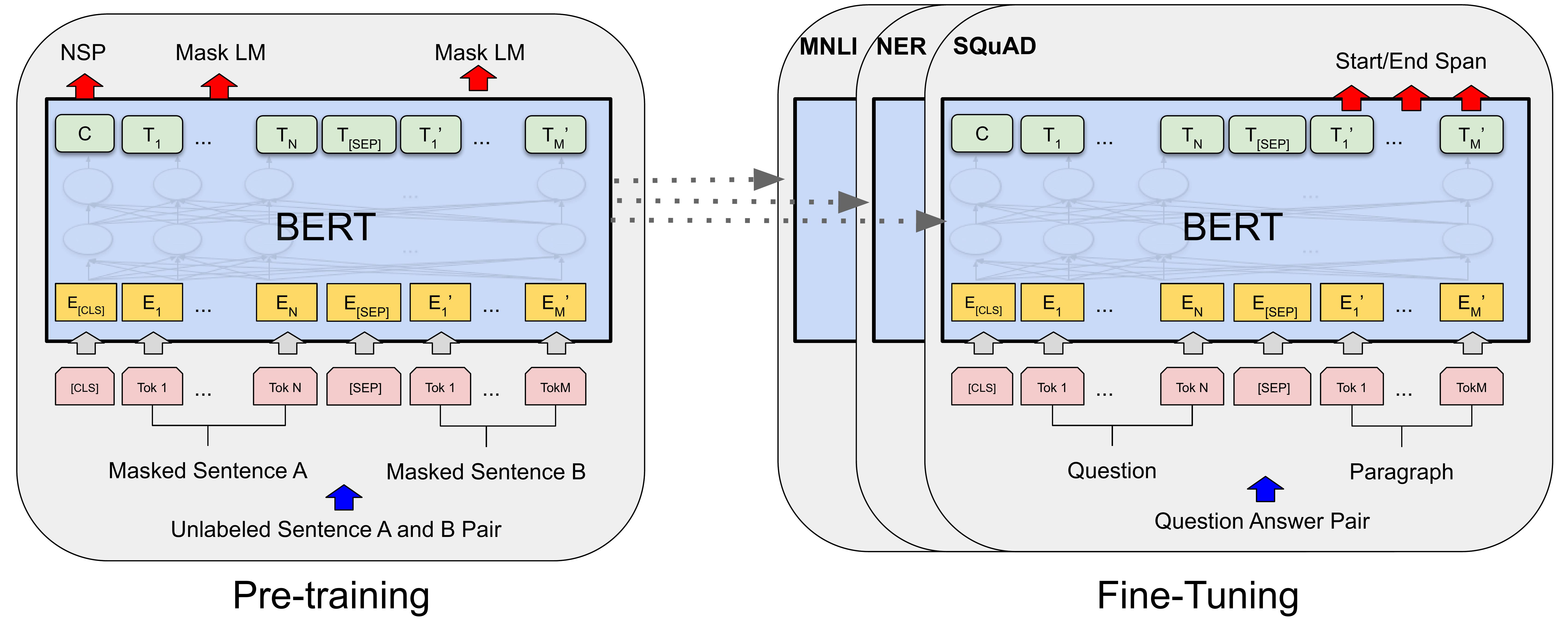
Huấn luyện BERT:
Hai nhiệm vụ chính được sử dụng để huấn luyện trước BERT:
- Masked Language Modeling (MLM): yêu cầu mô hình phải hiểu và dự đoán được từ trong câu, hiểu ngôn ngữ ở mức độ vi mô (micro-level).
- Next Sentence Prediction (NSP): yêu cầu mô hình phải hiểu và dự đoán được câu tiếp theo, hiểu ngôn ngữ ở mức độ vĩ mô (macro-level).
Cụ thể các task như sau.
Masked Language Modeling (MLM)
MLM là một phương pháp huấn luyện mô hình ngôn ngữ, trong đó một số từ trong câu được che đi ngẫu nhiên (masked) và mô hình phải dự đoán các từ bị che đó dựa trên ngữ cảnh xung quanh.
Cách hoạt động:
-
Che từ: Trong quá trình huấn luyện, một tỷ lệ phần trăm nhất định của các từ trong câu được chọn ngẫu nhiên và thay thế bằng một token đặc biệt, thường là “[MASK]”. Ví dụ, câu “Tôi thích ăn bánh mì” có thể được biến thành “Tôi thích ăn [MASK]”.
-
Dự đoán: Mô hình BERT sẽ cố gắng dự đoán từ bị che dựa trên các từ xung quanh. Trong trường hợp này, BERT sẽ cố gắng dự đoán từ “bánh mì”.
-
Tính toán mất mát: Mất mát (loss) được tính toán dựa trên sự khác biệt giữa từ dự đoán và từ gốc. Mất mát này được sử dụng để cập nhật các tham số của mô hình thông qua quá trình lan truyền ngược (backpropagation).
-
Lặp lại: Quá trình này được lặp lại nhiều lần trên một lượng lớn dữ liệu văn bản, giúp BERT học cách hiểu mối quan hệ giữa các từ và dự đoán các từ bị che một cách chính xác.
Tại sao MLM lại quan trọng?
-
Hiểu ngữ cảnh: MLM buộc BERT phải hiểu ngữ cảnh xung quanh một từ để dự đoán từ bị che. Điều này giúp BERT học được các biểu diễn từ phong phú, chứa đựng thông tin ngữ nghĩa và ngữ cảnh sâu sắc.
-
Học biểu diễn hai chiều: Vì BERT phải dự đoán từ bị che dựa trên cả các từ đứng trước và sau nó, MLM khuyến khích BERT học các biểu diễn hai chiều, nắm bắt được ngữ cảnh từ cả hai phía.
-
Tiền đề cho các nhiệm vụ khác: Các biểu diễn ngôn ngữ học được thông qua MLM có thể được sử dụng làm nền tảng cho nhiều nhiệm vụ NLP khác nhau như phân loại văn bản, nhận dạng thực thể, trả lời câu hỏi,…
Next Sentence Prediction (NSP)
NSP là một nhiệm vụ nhị phân (binary classification task), trong đó mô hình phải dự đoán xem hai câu có liên tiếp nhau trong văn bản gốc hay không.
Cách hoạt động:
-
Cặp câu: Trong quá trình huấn luyện, BERT nhận vào một cặp câu (sentence pair). Một trong hai câu này là câu tiếp theo của câu kia trong văn bản gốc (positive pair), trong khi câu còn lại được chọn ngẫu nhiên từ một phần khác của văn bản (negative pair).
-
Dự đoán: BERT sẽ phân loại cặp câu này là tích cực (hai câu liên tiếp) hoặc tiêu cực (hai câu không liên tiếp).
-
Tính toán mất mát: Mất mát được tính toán dựa trên sự khác biệt giữa dự đoán của mô hình và nhãn thực tế. Mất mát này được sử dụng để cập nhật các tham số của mô hình.
-
Lặp lại: Quá trình này được lặp lại nhiều lần trên một lượng lớn dữ liệu văn bản, giúp BERT học cách hiểu mối quan hệ giữa các câu.
Tại sao NSP lại quan trọng?
-
Hiểu cấu trúc đoạn văn: NSP giúp BERT học cách hiểu cấu trúc của đoạn văn và mối quan hệ giữa các câu trong đoạn. Điều này rất quan trọng đối với các nhiệm vụ như trả lời câu hỏi, tóm tắt văn bản, và hiểu ý nghĩa của toàn bộ đoạn văn.
- Học biểu diễn câu: NSP giúp BERT học các biểu diễn câu (sentence embeddings) có ý nghĩa, chứa đựng thông tin về mối quan hệ của câu đó với các câu xung quanh.
- Cải thiện hiệu suất trên các nhiệm vụ khác: Các nghiên cứu đã chỉ ra rằng việc huấn luyện trước với NSP có thể cải thiện hiệu suất của BERT trên nhiều nhiệm vụ NLP khác nhau.
Tinh chỉnh BERT cho các tác vụ cụ thể:
Mô hình pre-trained BERT đã học được các biểu diễn ngôn ngữ phong phú và hữu ích. Tuy nhiên, để BERT có thể thực hiện tốt một nhiệm vụ cụ thể (ví dụ: phân loại văn bản, trả lời câu hỏi, tóm tắt văn bản,…) thì cần phải tinh chỉnh (fine-tune) mô hình trên dữ liệu của nhiệm vụ đó.
Mô hình sẽ được thêm các lớp đầu ra, ví dụ như lớp classification cho bài phân loại văn bản, chuẩn bị dữ liệu và cho training với model mới. Thông thường mô hình tinh chỉnh chỉ được training cho các lớp mới thêm vào để bảo tồn kiến thức từ các lớp cũ của mô hình pre-training. Tuy nhiên nếu có đủ dữ liệu và các task mới có nhiều khác biệt so với dữ liệu lúc training ban đầu, vẫn có thể training cho toàn bộ mô hình.
References
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–4186.
