
Practical Statistics
Exploratory Data Analysis
Exploratory Data Analysis (EDA) thường là việc làm đầu tiên của một data scientist khi tiếp cận với dữ liệu. Mục đích để thăm dò, phân tích sơ bộ và đánh giá dữ liệu.
Cấu trúc dữ liệu
Các loại dữ liệu khác nhau được lưu ở nhiều cấu trúc khác nhau để phù hợp có việc lưu trữ và tính toán.
Dữ liệu cơ bản:
- Dữ liệu liên tục (Continuous): biển diễn các giá trị liên tục, thường là số thực, cơ bản như float, double, numeric.
- Dữ liệu rời rạc (Discrete): biểu diễn thường là số nguyên, cơ bản như integer.
- Dữ liệu phân loại (Categorical): cũng là dữ liệu rời rạc nhưng không có giá trị so sánh như Discrete, cơ bản như enums.
- Dữ liệu nhị phân (Binary): biểu diễn giá trị nhị phân (0, 1) hoặc luận lý true/false, cơ bản như boolean.
Dữ liệu bảng: Dữ liệu dạng bảng hay Rectangular, Frame là dữ liệu được lưu trữ dạng bảng gồm các dòng và các cột. Phổ biến nhất là Dataframe và database table. Trong máy tính, các bảng thường được lưu giống như 1 mảng 2 chiều.
Cấu trúc cơ bản gồm
- Columns: các cột thường được sử dụng để lưu trữ các biến cùng loại, như 1 feature cụ thể. phần tử trên một cột sẽ có cùng kiểu dữ liệu.
- Rows/Records: lưu trữ các mẫu (sample) dữ liệu.
Dữ liệu phi bảng tính:
Ngoài dữ liệu dạng bảng (Rectagular), các dữ liệu có thể lưu trữ ở dạng phi bảng tính (Nonrectangular Data Structures) để phục vụ cho việc tính toán và truy vấn phức tạp hơn hoặc phù hợp với bài toán cụ thể. Các dữ liệu phi bảng tính như Time-series, Graph.
Ước tính vị trí - Estimates of Location
Các biến trong dữ liệu có thể có rất nhiều giá trị, việc ước tính vị trí dữ liệu cho chúng ta biết được các giá trị điển hình của dữ liệu đó. Các phương pháp ước tính vị trí gồm:
- Mean: Giá trị trung bình của dữ liệu. Đây là giá trị cơ bản nhất và được dùng nhiều nhất để hiểu cơ bản về dữ liệu.
- Median: Giá trị trung vị, là giá trị nằm giữa của dữ liệu, có một nữa dữ liệu lớn hơn và 1 nữa dữ liệu nhỏ hơn. Giá trị median này đặc biệt dùng cho các bài toán khi có các phần tử quá lớn hoặc quá nhỏ khiến cho việc tính trung bình bị ảnh hưởng bởi các phần tử đó.
- Mode: giá trị xuất hiện nhiều nhất trong tập dữ liệu, giá trị này đặc biệt dùng cho kiểu dữ liệu rời rạc hay phân loại (categorical).
- Outlier: Các giá trị ngoại lệ, rất khác so với các giá trị còn lại trong tập dữ liệu.
Ước tính về sự thay đổi - Estimates of Variability
Ước tính vị trí (Estimates of Location) chỉ cho ta thông tin về 1 giá trị đặc trưng cho tập dữ liệu, ngoài ra chúng ta cũng muốn hiểu hơn về sự biến thiên, phân tán của các dữ liệu trong tập dữ liệu.
Các đặc tính thay đổi của dữ liệu thường có là:
- Mean Absolute Deviation - MAD (trung bình độ lệch tuyệt đối): được đo bằng trung bình của các giá trị tuyệt đối của hiệu giá trị trung bình (mean) và giá trị của điểm dữ liệu. nó đơn giản để tính xem trung bình các điểm dữ liệu lệch bao nhiêu so với giá trị trung bình.
- Variance (phương sai): Phương sai hay bình phương sai số được tính tương tự như MAD, tuy nhiên thay vì tính trị tuyệt đối của hiệu thì sẽ tính bình phương của hiệu. Việc tính bình phương cũng đảm bảo giá trị là không âm và các lệch nhiều thì giá trị của phương sai càng lớn do tính chất của việc tính bình phương.
- Standard Deviation: Độ lệch chuẩn được tính bằng căn bậc 2 của phương sai, độ lệch chuẩn dùng để đo mức độ phân tán của một tập hợp dữ liệu so với giá trị trung bình của nó. Nói cách khác, độ lệch chuẩn cho biết các số liệu trong tập dữ liệu có phân bố gần nhau hay xa nhau.Cũng gần giống như MAD, phương sai được dùng nhiều hơn trong thống kê.
- Percentile: còn gọi là bách phân vị, dùng để chỉ vị trí tương đối của một giá trị so với các giá trị còn lại trong một tập dữ liệu. Nói cách khác, percentile cho biết có bao nhiêu phần trăm dữ liệu có giá trị nhỏ hơn hoặc bằng giá trị đang xét. Median sẽ là Percentile 50 (50% dữ liệu có giá trị nhỏ hơn nó). Quartile hay tứ phân vị là một loại Percentile phổ biến thường được dùng, chỉ dữ liệu ở các mốc 25%, 50% và 75%.
Data Distribution
Boxp lot
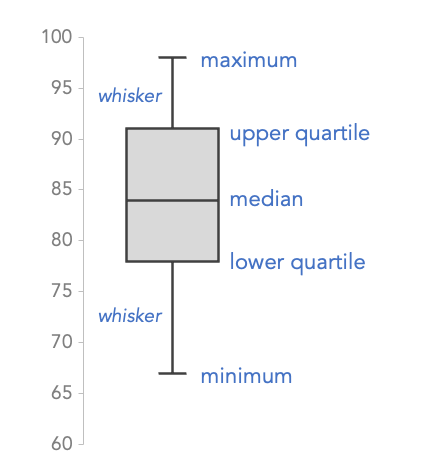
Boxplot là một cách biểu diễn phân bố dư liệu đơn giản nhưng rất hiệu quá dựa trên phân vị.
Box là một hình chữ nhật thể 2 mốc phân vị Q75 và Q25. Trung tâm hình chữ nhật có đánh dấu vị trí trung vị (median) hay Q50.
Có 2 râu tại maximun và minimun là 2 giá trị được xem là giới hạn của các dữ liệu bình thường. Các điểm dữ liệu nằm ngoài 2 điểm này được xem là outliers.
Cách tính 2 râu này có nhiều cách, có thể là Q5 và Q95, hoặc có thể tính bằng khoảng cách từ nó đến Q25 và Q75 là 1.5*IQR, với IQR (interquartile range) là khoảng cách từ Q75 - Q25 (chiều dài của hình chữ nhật).
Boxplot thể hiện được mức độ phân bố của dữ liệu, độ lệch của phân bố và giới hạn outliers.
Histogram
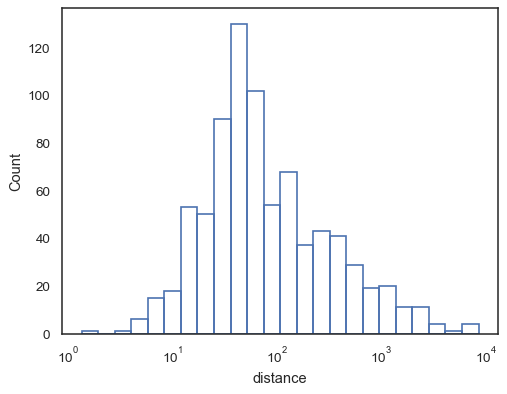
Histogram là một cách biểu diển cổ điển của phân bố dữ liệu, giá trị của dữ liệu được thể hiện bằng các cột rời rạc, với chiều cao của các cột thể hiện số lượng của các điểm dữ liệu có giá trị bằng giá trị cột đó đại diện.
Density plot
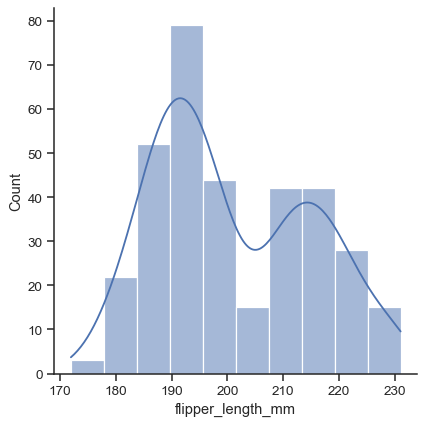
Density plot hay distribution plot là cách biểu diễn tương tự với Histogram, tuy nhiên density plot vẽ các đường cong thể hiện mực độ phân bố của dữ liệu thay vì biển diển bằng các cột rời rạc. Trong hình mô tả, đường cong được đè lên trên histogram là density plot của phân bố.
Khám phá Binary và Categorical Data
Đối với dữ liệu Binary và Categorical, chỉ số thống kê cơ bản Mode, thể hiện giá trị nào có số lượng phổ biến nhất trong tập dữ liệu.
Các loại biểu đồ thường được sử dụng để biểu diễn phân bố của Binary và Categorical Data là Bar charts, Pie charts.
Correlation
Correlation coefficient Hệ số tương quan (Correlation coefficient) là thước đo thống kê cho biết mức độ liên hệ tuyến tính giữa 2 biến số. Dựa vào chỉ số này có thể xem 2 biến có xu hướng thay đổi cùng chiều hay ngược chiều, mức độ thay đổi mạnh hay yếu.
Có các loại phương pháp tính hệ số phổ biến:
- Pearson: đo lượng mức độ tuyến tính của 2 biến số. Phương pháp này có giả định dữ liệu tuân theo phân phối chuẩn và nhạy cảm với outliers.
- Spearman: đo lường mức độ đồng điệu (Monotonic) của 2 biến số, phương pháp này không giả định về phân phối phải chuẩn và ít nhạy cảm với outliers.
- Kendall: đo lường mức độ tương đồng (Concordance) của 2 biến, phương pháp này cũng không giả định về phân phối phải là chuẩn, và ít nhạy cảm với outliers hơn cả 2 phương pháp trước.
Correlation matrix
Một bảng với các biến được hiển thị trên cả hàng và cột, và giá trị ô là mối tương quan giữa các biến. Correlation matrix được sử dụng để xem tổng quan về mức độ tương đồ của các biến hoặc feature của dữ liệu trong bước EDA.
Scatterplot
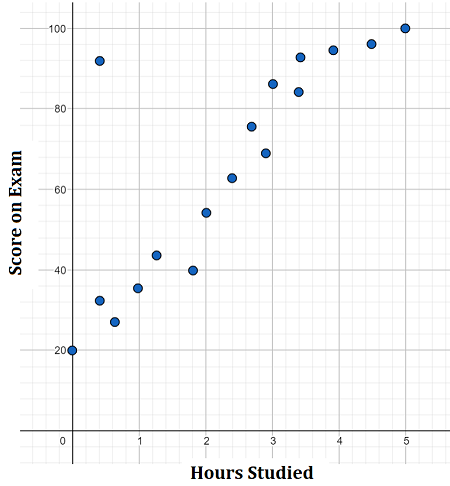
Scatterplot là cách hiển thị đơn giản để thể hiện mức đọ tương đồng của 2 biến. Việc hiển thị có thể giúp người xem hình dung về mức độ tương qua và loại tương quan của 2 biến.
Exploring Two or More Variables
Tương tự với phân tích đơn biến (univariate analysis), phân tích 2 biến (bivariate analysis) và đa biến (multivariate analysis) cũng quan trọng, các biến thường được hiển thị (visualize) cùng nhau trên 1 đồ thị, biểu diễn tương quan bằng Contour plots hoặc Violin plots.
Data and Sampling Distributions
Lấy mẫu có nhiều ý nghĩa trong phân tích và tính toán dữ liệu, không chỉ làm nhỏ hơn để tính nhanh hơn mà còn giúp loại bỏ các yếu tố không tốt của dữ liệu như mất cân bằng trong dữ liệu. Chương này, ta sẽ cùng tìm hiểu về việc lấy mẫu dữ liệu.
Random Sampling and Sample Bias
Selection Bias hay thiên lệch lựa chọn là hiện tượng say ra khi mẫu được lựa chọn không đại diện cho tập dữ liệu ta muốn nghiên cứu. Điều này có thể dẫn tới kết quả không chính xác hoặc sai lệch, vì mẫu không phản ánh được các đặc điểm của dữ liệu.
Regression to the mean hay hồi quy về giá trị trung bình mô tả hiện tượng các dữ liệu/quan sát cực đoan (extreme observations) có xu hướng sẽ thay đổi về điểm trung bình hoặc giá trị kỳ vọng khi được đo lại hoặc qua các lần quan sát sau.
Ví dụ điểm số của một học sinh cao bất thường ở 1 bài kiểm tra sẽ có xu hướng về lại giá trị trung bình sau các bài thi tiếp theo. Lý do có thể là vì bài kiểm tra vừa rồi đề dễ hoặc học sinh này rất may mắn. Việc hiểu và đánh giá đúng Regression to the mean giúp ta tránh hiểu nhầm và rút ra các kết luận không chính xác từ các quan sát ban đầu.
Sampling Distribution of a Statistic
Sampling Distribution hay thống kê mẫu đề cập đến sự phân phối của một số thống kê trên một số mẫu lấy từ một quần thể (population).
Central Limit Theorem (CLT), hay Định lý giới hạn trung tâm, là một trong những định lý cơ bản và quan trọng nhất trong lý thuyết xác suất và thống kê. Định lý này phát biểu rằng:
Khi kích thước mẫu đủ lớn, phân phối của trung bình mẫu (hoặc tổng mẫu) sẽ xấp xỉ phân phối chuẩn (Gaussian), bất kể phân phối của quần thể ban đầu là gì.
Quần thể ban đầu: Có thể có bất kỳ phân phối nào, ví dụ: phân phối đều, phân phối mũ, phân phối lệch, v.v.
Trung bình mẫu: Là trung bình của một mẫu ngẫu nhiên được lấy từ quần thể. Nếu bạn lấy nhiều mẫu ngẫu nhiên từ quần thể, tính trung bình của từng mẫu và sau đó vẽ đồ thị phân phối của các giá trị trung bình mẫu, thì phân phối đó sẽ dần dần trở nên gần với phân phối chuẩn khi kích thước mẫu tăng lên.
Kích thước mẫu lớn: Định lý này bắt đầu đúng khi kích thước mẫu (số lượng phần tử trong mỗi mẫu) đủ lớn. Mặc dù không có một ngưỡng chính thức cho “đủ lớn”, nhưng thường thì kích thước mẫu từ 30 trở lên là đủ để phân phối của trung bình mẫu gần với phân phối chuẩn.
Standard Error (SE), hay Sai số chuẩn, là một khái niệm quan trọng trong thống kê, dùng để đo lường sự phân tán (biến động) của một ước lượng thống kê, thường là trung bình mẫu, so với giá trị trung bình thực sự của quần thể.
-
Định nghĩa: Standard Error (SE) là độ lệch chuẩn của phân phối mẫu của một ước lượng thống kê (thường là trung bình mẫu). Nó cho biết mức độ không chắc chắn hoặc độ biến động của ước lượng này khi thực hiện nhiều lần lấy mẫu từ cùng một quần thể.
-
Sự khác biệt với độ lệch chuẩn: Độ lệch chuẩn (standard deviation) của quần thể đo lường sự phân tán của các giá trị trong quần thể. Trong khi đó, sai số chuẩn (SE) đo lường sự phân tán của các trung bình mẫu (hoặc các ước lượng thống kê khác) khi ta lấy nhiều mẫu từ quần thể. Nói cách khác, SE cho biết trung bình mẫu có thể dao động bao nhiêu quanh trung bình quần thể.
Công thức tính Standard Error:
Đối với trung bình mẫu (\(\bar{X}\)), công thức sai số chuẩn là:
\[ SE = \frac{\sigma}{\sqrt{n}} \]
- \(\sigma\) là độ lệch chuẩn của quần thể.
- \(n\) là kích thước mẫu.
Nếu độ lệch chuẩn của quần thể (\(\sigma\)) không có sẵn (ví dụ trong các nghiên cứu thực tế), ta có thể thay thế bằng độ lệch chuẩn mẫu (\(s\)), và công thức trở thành:
\[ SE = \frac{s}{\sqrt{n}} \]
Ý nghĩa của Standard Error:
-
Đo sự biến động: SE cung cấp một phép đo về mức độ biến động của trung bình mẫu so với trung bình quần thể. Nếu SE nhỏ, điều đó có nghĩa là trung bình mẫu gần với trung bình quần thể, và ngược lại.
-
Kích thước mẫu: SE giảm khi kích thước mẫu \(n\) tăng. Điều này phản ánh rằng với mẫu lớn, ta sẽ có ước lượng trung bình chính xác hơn về trung bình quần thể (vì trung bình mẫu có xu hướng tiệm cận trung bình quần thể khi \(n\) lớn hơn).
-
Độ tin cậy: Khi SE nhỏ, ta có thể tự tin hơn vào kết quả ước lượng. Ngược lại, SE lớn cho thấy sự không chắc chắn cao về giá trị trung bình mẫu, dẫn đến độ tin cậy thấp hơn.
Bootstrap
Bootstrap sampling là một kỹ thuật thống kê được sử dụng rộng rãi để ước lượng các thông số của một phân phối xác suất khi không có thông tin chi tiết về phân phối đó. Thay vì đưa ra các giả định về phân phối, bootstrap sampling sử dụng lại dữ liệu hiện có để tạo ra nhiều mẫu dữ liệu mới (gọi là bootstrap samples).
Về mặt khái niệm, bạn có thể tưởng tượng bootstrap là sao chép (duplicate) mẫu gốc hàng nghìn hoặc hàng triệu lần để bạn có một quần thể giả định bao gồm tất cả thông tin từ mẫu gốc của bạn (chỉ lớn hơn). Sau đó, bạn có thể lấy mẫu từ quần thể giả định này để ước tính phân phối mẫu.
Bootstrap là một phương pháp mạnh mẽ và có thể áp dụng trong nhiều tình huống khi các phương pháp thống kê truyền thống không áp dụng được hoặc khi ta không có thông tin về phân phối của quần thể. Cụ thể, bạn nên sử dụng Bootstrap sampling trong các trường hợp sau:
- Khi không biết phân phối của quần thể.
- Khi không thể tính toán tham số trực tiếp.
- Để ước lượng khoảng tin cậy (Confidence Interval)
- Khi các giả định trong mô hình không thỏa mãn
- Kiểm định giả thuyết (Hypothesis testing)
Confidence Intervals
Khoảng tin cậy (Confidence Interval - CI) Cho phép ta đánh giá độ tin cậy của một ước tính. Một phương pháp tính khoảng tin cậy là dùng boostrap để lấy mẫu, rồi tính khoảng tin cây từ kết quả lấy mẫu của Boostrap như từ range 5%-95% giá trị sẽ là khoảng tin cậy 90%.
Phân phối chuẩn
Phân phối chuẩn - Normal Distribution - Gauss Distribution là phân phối quan trọng nhất của thống kê, nó có giá trị trung bình bằng 0 và độ lệch chuẩn bằng 1.
